Decentralized AI in Tourism and Hospitality: Personalized Experiences
AI agents are transforming the landscape of data analysis by automating complex processes, enhancing decision-making, and uncovering valuable insights from vast datasets. These intelligent systems leverage machine learning, natural language processing, and advanced algorithms to analyze data at unprecedented speeds, identify patterns, and predict trends with remarkable accuracy. In today’s data-driven world, businesses across industries rely on AI agents to gain a competitive edge, streamline operations, and make informed decisions based on real-time insights.
 AI Agents In Data Analysis
AI Agents In Data AnalysisThis ultimate guide delves into how AI agents are reshaping data analysis, from predictive analytics and data visualization to anomaly detection and automated reporting. We will explore the technologies behind these AI-driven tools, how they integrate with existing data systems, and the significant impact they have on industries ranging from healthcare to finance.
By understanding the capabilities of AI agent development, organizations can harness their full potential to unlock new opportunities, improve efficiency, and ultimately drive growth in an increasingly data-centric world. Whether you’re a business leader or a data professional, this guide will equip you with the knowledge to leverage AI for superior data-driven insights.
Table of ContentWhat is AI Agents In Data Analysis?Types of AI Agents for Data Analysis Tasks
How AI Agents Learn from Data?
How do AI Agents for Data Analysis Work?
The Role of AI Agents in Modern Data Analysis
Benefits of Using AI Agents for Data-Driven Insights
How do Multi-Agents Help in Qualitative Data Analysis?
How to Build LLM-Based AI Agents for Data Analysis?
Use Cases of AI Agents in Data Analysis
Overcoming Challenges in Implementing AI Agents for Data Analysis
The Future of AI Agents in Data Analysis
ConclusionWhat is AI Agents In Data Analysis?
AI agents in data analysis refer to intelligent systems that use artificial intelligence technologies, such as machine learning, deep learning, and natural language processing, to automate the process of analyzing and interpreting large datasets. These AI agents are designed to quickly process complex data, identify patterns, uncover trends, and generate insights that would otherwise take humans significantly longer to discover. Unlike traditional data analysis methods, AI agents can work with unstructured data, provide real-time analytics, and make predictions with high accuracy.
They are equipped with algorithms that allow them to learn from historical data, adapt to new information, and improve their performance over time. AI agents are increasingly being used in various industries, such as healthcare, finance, marketing, and supply chain management, to drive data-driven decision-making, optimize operations, and enhance strategic planning. By automating repetitive tasks and delivering actionable insights, AI agents not only save time and resources but also help businesses unlock valuable opportunities, reduce errors, and stay competitive in a data-driven world.
Types of AI Agents for Data Analysis TasksAI agents for data analysis can be classified into several types, each suited for different tasks and use cases. These agents leverage various AI techniques, from machine learning to natural language processing (NLP), to perform data-driven tasks more efficiently and accurately. Here’s a breakdown of the main types of AI agents used in data analysis:
 1. Supervised Learning Agents
1. Supervised Learning Agents- Description: These AI agents are trained on labeled datasets, where the correct output is known. The goal of these agents is to learn patterns and relationships in the data to predict or classify future outcomes.
- Regression: Predicting continuous values (e.g., house prices, stock prices).
- Classification: Assigning labels to data (e.g., customer churn, fraud detection).
- Example Tools: Random Forest, Support Vector Machines (SVM), and Neural Networks.
- Use Cases: Predicting customer behavior, financial forecasting, and image classification.
- Description: These AI agents work with unlabeled data, trying to identify hidden patterns and structures within the dataset without predefined categories or outputs.
- Clustering: Grouping similar data points together (e.g., customer segmentation, anomaly detection).
- Dimensionality Reduction: Reducing the number of features in a dataset while maintaining essential information (e.g., PCA, t-SNE).
- Example Tools: K-Means Clustering, DBSCAN, and Principal Component Analysis (PCA).
- Use Cases: Market segmentation, anomaly detection, and image compression.
- Description: These agents learn through trial and error, receiving feedback from the environment in the form of rewards or penalties based on their actions. They are ideal for tasks that involve decision-making over time.
- Optimization: Learning to maximize rewards through decision-making (e.g., stock trading algorithms, supply chain optimization).
- Strategy Development: Learning long-term strategies and adapting to dynamic environments (e.g., game-playing AI, robotics).
- Example Tools: Q-Learning, Deep Q-Networks (DQN), and Proximal Policy Optimization (PPO).
- Use Cases: Autonomous driving, robotics, dynamic pricing models, and game-based decision-making.
- Description: NLP agents process and analyze human language data. These agents help understand, interpret, and generate natural language, which is crucial for extracting insights from unstructured text data.
- Text Classification: Categorizing text data (e.g., sentiment analysis, topic modeling).
- Named Entity Recognition (NER): Identifying entities (e.g., names, dates, locations) in text data.
- Text Summarization: Condensing large volumes of text into shorter, meaningful summaries.
- Question Answering: Extracting answers from documents or datasets based on user queries.
- Example Tools: BERT, GPT-3, Spacy, and NLTK.
- Use Cases: Chatbots, sentiment analysis, document summarization, and customer service automation.
- Description: These AI agents are designed to identify unusual patterns or outliers in data. They are particularly useful in applications where detecting deviations from the norm is important (e.g., fraud detection, cybersecurity).
- Outlier Detection: Identifying data points that deviate significantly from the expected pattern (e.g., fraudulent transactions).
- Novelty Detection: Identifying new or previously unseen patterns that might indicate a change in behavior.
- Example Tools: Isolation Forest, One-Class SVM, Autoencoders.
- Use Cases: Fraud detection in financial transactions, intrusion detection in cybersecurity, and predictive maintenance in manufacturing.
- Description: These agents are optimized to analyze sequential data that is collected over time. They are especially useful for forecasting future trends and making predictions based on temporal patterns.
- Trend Forecasting: Predicting future values based on historical data (e.g., sales forecasting, weather prediction).
- Seasonality Detection: Identifying regular patterns or cycles within data (e.g., quarterly sales patterns).
- Anomaly Detection: Detecting unusual behaviors over time that may indicate problems (e.g., system failures).
- Example Tools: ARIMA, Prophet, Long Short-Term Memory (LSTM) networks.
- Use Cases: Stock price prediction, demand forecasting, and predictive maintenance in industrial settings.
- Description: These AI agents generate new data that mimics the characteristics of the original dataset. They are commonly used for tasks such as data augmentation or creating synthetic data for training other AI models.
- Data Augmentation: Generating additional data points to supplement a given dataset, helping improve model performance.
- Image and Text Generation: Creating new images or text based on learned patterns from the training data.
- Example Tools: GANs (Generative Adversarial Networks), Variational Autoencoders (VAEs).
- Use Cases: Generating synthetic medical data for training, text generation for chatbots, and enhancing machine learning models with more training data.
- Description: These AI agents combine different AI techniques, such as supervised, unsupervised, and reinforcement learning, into a single system to solve complex, multi-faceted data analysis problems.
- Multi-task Learning: Solving multiple tasks at once, where different parts of the model learn from different types of data or objectives.
- Integrated Decision Making: Using reinforcement learning for decision-making with a foundation built on supervised or unsupervised learning models.
- Example Tools: Deep Reinforcement Learning (DRL), Multi-Task Neural Networks.
- Use Cases: Complex recommendation systems, personalized content delivery, and autonomous systems that require multi-level decision-making.
- Description: Deep learning agents use neural networks with multiple layers (deep neural networks) to analyze large amounts of data, particularly unstructured data like images, video, and audio.
- Image Classification: Identifying objects or patterns in images (e.g., medical imaging, facial recognition).
- Speech Recognition: Converting spoken language into text (e.g., virtual assistants, transcription services).
- Natural Language Understanding: Understanding and generating human language in text or speech (e.g., chatbots, translation systems).
- Example Tools: Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Transformer models.
- Use Cases: Image and video analysis, speech-to-text applications, and language translation.
- Description: These AI agents focus on making complex models more interpretable and understandable to humans. They aim to provide insights into why an AI model made a certain decision, which is crucial for trust and accountability.
- Model Interpretability: Making machine learning models and predictions transparent and understandable to non-experts.
- Feature Attribution: Identifying which features or data points most influence a model’s prediction.
- Example Tools: LIME (Local Interpretable Model-Agnostic Explanations), SHAP (Shapley Additive Explanations).
- Use Cases: Regulatory compliance, healthcare diagnostics, and financial decision-making where accountability is critical.
- Description: These AI agents are designed to assist users with data exploration by offering insights, visualizations, and suggestions without requiring deep technical expertise. They often use natural language interfaces to simplify interactions.
- Data Exploration: Allowing users to ask questions about their data and get instant visualizations and answers.
- Automated Insights: Automatically generating insights based on the data, such as correlations, trends, and anomalies.
- Example Tools: IBM Watson Analytics, Microsoft Power BI with AI integration.
- Use Cases: Business intelligence dashboards, data-driven decision-making, and self-service analytics for non-technical users.
AI agents for data analysis come in various forms, each suited to different data types, tasks, and industries. From supervised learning agents that predict outcomes to deep learning agents capable of processing complex unstructured data, the applications are vast and growing. As AI technology continues to advance, the role of these agents will expand, enabling more efficient, insightful, and automated data analysis across industries.
How AI Agents Learn from Data?AI agents learn from data through a process called machine learning (ML), where algorithms are trained on data to recognize patterns, make predictions, and improve their performance over time. Here’s a simplified breakdown of how this process works:
 1. Data Collection
1. Data Collection- Input Data: AI agents need large amounts of data to learn. This data can come in many forms, such as images, text, videos, or sensor readings. For example, a self-driving car collects data from its cameras, radar, and other sensors.
- Preprocessing: Data is often cleaned and preprocessed to ensure it’s usable. This step may involve removing duplicates, handling missing values, and normalizing data (scaling values to a consistent range).
- Choosing a Model: Depending on the task, an appropriate AI model or algorithm is chosen. Common models include decision trees, neural networks, and support vector machines. For deep learning tasks, convolutional neural networks (CNNs) or recurrent neural networks (RNNs) might be used.
- Supervised Learning: The model is trained on labeled data (input-output pairs). For example, a model could learn to classify images of cats and dogs by using labeled examples (images with tags indicating “cat” or “dog”).
- Unsupervised Learning: The model is trained on unlabeled data and tries to find patterns or groupings on its own, like identifying clusters of similar data points.
- Reinforcement Learning: The AI agent learns by interacting with an environment and receiving feedback (rewards or penalties) for its actions, helping it improve over time, like teaching a robot to navigate a maze.
- Learning from Data: During the training phase, the AI algorithm makes predictions or decisions based on input data, then compares those predictions to the correct outcomes (labels or feedback). For example, in supervised learning, the algorithm compares its prediction to the true label and adjusts its internal parameters accordingly to reduce errors.
- Optimization: The model uses optimization techniques, like gradient descent, to minimize the error or loss function, which measures how far off the predictions are from the actual values. Over time, the model’s parameters are fine-tuned to make more accurate predictions.
- After training, the AI model is tested on a separate dataset (often called a test set) that it hasn’t seen before. This is important to ensure that the model generalizes well to new, unseen data.
- Metrics: Performance is measured using various metrics, depending on the task. For classification tasks, accuracy, precision, recall, and F1 score are common metrics. For regression tasks, mean squared error (MSE) might be used.
- Continuous Learning: AI agents typically improve with more data and iterations. If the model performs poorly, it might need more data, better preprocessing, or a different model.
- Fine-Tuning: After the model is deployed, it can continue to learn and adapt based on new data or feedback from its environment. For example, a recommendation system might continually improve based on user interactions.
- Once trained and evaluated, the AI model can be deployed to make decisions, predictions, or automate tasks. For example, in autonomous vehicles, the AI agent uses learned patterns from its data to make driving decisions in real time.
By continuously iterating through these steps, AI agents can learn from data, adapt to changing environments, and improve over time, leading to more accurate predictions and better decision-making.
How do AI Agents for Data Analysis Work?AI agents for data analysis work by leveraging various artificial intelligence techniques to process, analyze, and generate insights from data. These agents operate autonomously or semi-autonomously to perform specific tasks, such as pattern recognition, prediction, classification, and optimization. Here’s a general breakdown of how AI agents for data analysis work:
 1. Data Collection and Preprocessing
1. Data Collection and Preprocessing- Input: The first step involves gathering raw data from multiple sources, such as databases, APIs, sensors, or even user inputs. This data may come in structured (tables, spreadsheets), unstructured (text, images), or semi-structured (JSON, XML) formats.
- Preprocessing: Before analysis, AI agents often perform data cleaning and preprocessing. This includes:
- Handling Missing Data: Filling in missing values using techniques like imputation or removing rows/columns with excessive missing data.
- Data Normalization: Standardizing data values to a common scale (e.g., scaling features between 0 and 1) to avoid biases caused by differing magnitudes.
- Feature Engineering: Creating new features or transforming existing ones to make the data more useful for analysis (e.g., converting categorical variables to numerical values).
- Data Transformation: Converting data into a form suitable for analysis, such as encoding categorical variables or creating time series from timestamps.
- Choosing the Right Model: The AI agent selects an appropriate model or algorithm for the task at hand. The selection is based on the nature of the data and the type of analysis required. Common types of models include:
- Supervised Learning Models: These models are trained on labeled data and are used for classification (e.g., identifying categories) or regression (e.g., predicting numeric values).
- Unsupervised Learning Models: These models work with unlabeled data and focus on discovering hidden patterns, groupings (clustering), or reducing dimensionality.
- Reinforcement Learning Models: These agents learn through trial and error, optimizing actions based on rewards or penalties.
- Deep Learning Models: These use neural networks to process complex data, particularly unstructured data like images, text, and audio.
- Training: During the training phase, the AI agent adjusts the parameters of the selected model by feeding it historical or labeled data. The agent continuously updates its model to minimize the error in its predictions or classifications.
- Supervised Learning: The agent uses labeled data to adjust its parameters so that the predictions match the actual labels as closely as possible.
- Unsupervised Learning: The agent seeks to identify patterns or relationships in the data, such as clustering similar data points together.
- Reinforcement Learning: The agent explores different actions, receives feedback from the environment (rewards or penalties), and adjusts its strategy over time to maximize rewards.
- Making Predictions: Once the model is trained, the AI agent applies it to new or unseen data (test data) to make predictions or classifications. For example:
- Classification: In a spam email filter, the AI agent would classify new emails as either spam or not based on patterns learned during training.
- Regression: In a stock price prediction task, the agent predicts the future value of a stock based on historical data.
- Anomaly Detection: The agent identifies outliers or unusual patterns, such as fraud in transaction data or anomalies in network traffic.
- Real-Time Decision-Making: Some AI agents, particularly those using reinforcement learning or deep learning, make real-time decisions based on the data they receive continuously. For example, an autonomous vehicle uses sensor data in real-time to make driving decisions.
- Continuous Learning: Many AI agents are designed to adapt and improve their performance over time. This process is known as online learning or continuous learning, where the model updates itself as new data is received. In dynamic environments, agents may refine their strategies and predictions based on new trends or information.
- Feedback Loops: AI agents can be equipped with feedback loops that allow them to adjust their models after receiving feedback on the accuracy of their predictions or actions.
- Reinforcement Learning: In environments where agents learn from their actions (e.g., stock trading or robotics), the agent updates its policy or strategy based on the rewards or penalties received after each action.
- Data Interpretation: Once predictions or classifications are made, the AI agent often interprets the results to generate meaningful insights. This may involve:
- Feature Importance: Identifying which features or variables in the data had the most influence on the model’s predictions. This is particularly useful in models like decision trees or random forests.
- Trend Analysis: Identifying patterns or trends in time-series data (e.g., rising demand for a product, changing customer preferences).
- Anomaly Explanation: In anomaly detection tasks, the agent may highlight the factors contributing to the detection of an anomaly (e.g., a fraudulent transaction).
- Data Visualization: Some AI agents generate visualizations (graphs, heatmaps, or charts) to help analysts better understand the insights and make data-driven decisions. This is often an important part of business intelligence tools and dashboard systems.
- Automation: In certain applications, AI agents can autonomously act on the data insights they generate. For example:
- Recommendation Systems: An AI agent might suggest products to users based on their browsing behavior or purchase history (e.g., in e-commerce platforms).
- Optimization Tasks: In supply chain management, the AI agent may optimize delivery routes based on real-time data (traffic, weather) and historical patterns.
- Real-Time Monitoring: In areas like cybersecurity or fraud detection, AI agents continuously monitor data streams and automatically trigger responses when suspicious patterns are detected, such as blocking a fraudulent transaction or raising an alert to security personnel.
- Model Evaluation: After making predictions or classifications, the AI agent evaluates its performance using various metrics:
- Accuracy: How often the model makes correct predictions.
- Precision and Recall: In classification tasks, precision measures how many of the predicted positive cases were actually positive, and recall measures how many of the actual positive cases were correctly predicted.
- Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE): For regression tasks, these metrics evaluate how close the predictions are to the actual values.
- Confusion Matrix: For classification tasks, this matrix helps assess the types of errors made by the model, such as false positives or false negatives.
- Adjustments: If the model’s performance is not satisfactory, the AI agent may adjust its parameters, perform hyperparameter tuning, or even retrain the model with additional data.
AI agents for data analysis work by automating the entire data analysis pipeline collecting, cleaning, processing, analyzing, and generating insights from data. They use machine learning, deep learning, and other AI techniques to identify patterns, make predictions, and support decision-making. By continually adapting and learning from new data, these agents can improve their performance and handle increasingly complex tasks, making them invaluable tools for data-driven organizations.
The Role of AI Agents in Modern Data AnalysisAI agents play a crucial role in modern data analysis by automating, enhancing, and accelerating the process of extracting insights from vast amounts of data. They bring advanced capabilities such as pattern recognition, anomaly detection, predictive modeling, and decision-making support to the table. Here’s a breakdown of how AI agents are reshaping data analysis:
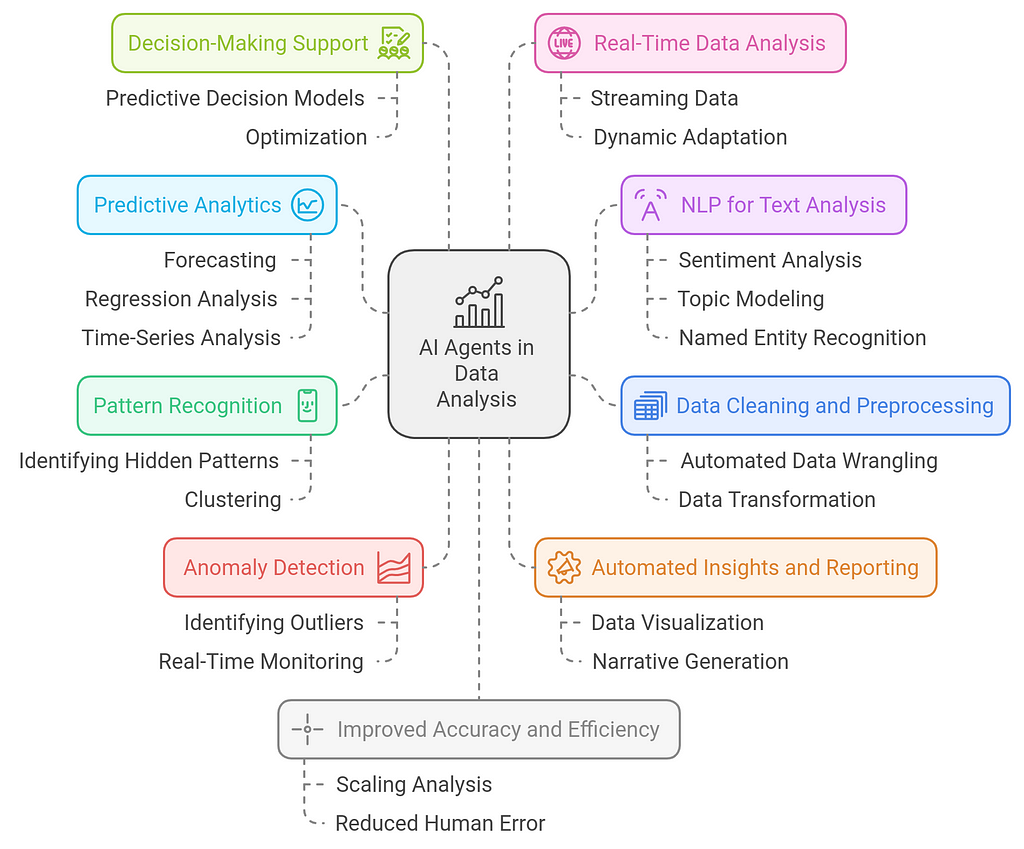 1. Data Cleaning and Preprocessing
1. Data Cleaning and Preprocessing- Automated Data Wrangling: AI agents help automate the tedious task of cleaning and preprocessing raw data. They can identify and fix issues such as missing values, inconsistencies, and outliers, ensuring that data is in the best possible shape for analysis.
- Data Transformation: AI can also assist in transforming data into formats suitable for analysis. This could involve normalizing values, encoding categorical data, or aggregating information from multiple sources.
- Identifying Hidden Patterns: AI agents excel at finding patterns in large datasets that humans might miss. They can analyze relationships between variables, detect trends over time, and spot correlations that can drive business insights.
- Clustering: In unsupervised learning, AI can group similar data points together (clustering), such as segmenting customers based on purchasing behavior or grouping products that are often bought together.
- Forecasting: AI agents use historical data to predict future events, trends, or outcomes. For instance, they can predict stock market prices, customer demand, or product performance, allowing businesses to make data-driven decisions.
- Regression Analysis: AI uses regression techniques to predict continuous variables. This might include predicting a house’s market value based on features like size, location, and amenities or estimating future sales based on past performance.
- Time-Series Analysis: AI can analyze time-series data to forecast future values, identify seasonal patterns, or detect anomalies, helping businesses plan for the future with greater accuracy.
- Identifying Outliers: AI agents are particularly adept at detecting anomalies or outliers in data. These could be fraudulent transactions in banking, unusual patterns in sensor data, or errors in manufacturing processes.
- Real-Time Monitoring: AI systems can monitor incoming data streams in real-time and flag any anomalies or irregularities, enabling faster responses to critical issues like network intrusions or equipment malfunctions.
- Sentiment Analysis: AI can analyze text data from sources like social media, customer reviews, or news articles to assess public sentiment or gauge customer opinions. This is valuable for market research, brand management, and customer service.
- Topic Modeling: AI agents can extract key topics from large collections of text, such as understanding common themes in customer feedback or categorizing articles based on content.
- Named Entity Recognition (NER): AI can identify and classify entities (such as names, dates, and locations) in unstructured text, which helps in extracting structured insights from documents, emails, or news articles.
- Data Visualization: AI can generate interactive, real-time dashboards and visualizations, helping users quickly understand complex datasets. It can recommend the best ways to represent data, such as through heatmaps, scatter plots, or time-series graphs, to communicate findings effectively.
- Narrative Generation: Some AI systems can automatically generate textual summaries or insights based on the data. These AI agents analyze patterns and trends and then produce reports that highlight the key takeaways, making it easier for analysts or business users to digest findings without manually combing through data.
- Predictive Decision Models: AI agents can integrate predictive models into decision-making processes, helping organizations anticipate outcomes and take proactive actions. For example, in marketing, AI can suggest which customers are most likely to convert based on historical data.
- Optimization: AI can optimize decision-making by using algorithms to find the best solutions to problems, whether it’s optimizing supply chains, scheduling, resource allocation, or pricing strategies.
- Streaming Data: AI agents can process real-time data from sensors, social media, or IoT devices, providing immediate insights and facilitating quick decision-making. This is especially valuable in fields like e-commerce, where customer behavior can be analyzed and acted upon in real-time, or in healthcare for real-time patient monitoring.
- Dynamic Adaptation: AI systems can adapt to changing data patterns, continuously learning from new inputs and adjusting their models over time. This dynamic learning makes AI particularly effective in environments where data evolves rapidly, like financial markets or real-time traffic analysis.
- Scaling Analysis: AI agents can handle and process much larger datasets than human analysts, speeding up the analysis process. This capability is particularly useful in big data environments where traditional methods would be too slow or resource-intensive.
- Reduced Human Error: By automating repetitive tasks, AI reduces the likelihood of human error and ensures more consistent results in data analysis.
- Bias Detection: AI agents can help detect biases in data or algorithms, ensuring that analysis is more fair and objective. This is crucial in areas such as hiring, lending, or criminal justice, where biased data could lead to discriminatory outcomes.
- Ethical Decision-Making: AI can be used to flag ethical concerns within data, such as privacy issues or the use of sensitive personal information, ensuring compliance with data protection regulations.
By leveraging AI’s advanced capabilities, businesses and organizations can unlock the full potential of their data, leading to smarter, faster, and more informed decision-making across a wide range of industries.
Benefits of Using AI Agents for Data-Driven InsightsUsing AI agents for data-driven insights offers several significant benefits, enabling organizations to harness the full potential of their data more efficiently and effectively. Here are some key advantages:
 1. Speed and Efficiency
1. Speed and Efficiency- Faster Data Processing: AI agents can process vast amounts of data at high speeds, far exceeding human capabilities. This allows businesses to extract insights in real-time or near real-time, which is crucial for fast-paced decision-making.
- Automated Analysis: AI can automate repetitive tasks like data cleaning, preparation, and initial analysis, freeing up time for human analysts to focus on interpreting results and making strategic decisions.
- Predictive Analytics: AI agents can analyze historical data to make predictions about future trends, helping organizations make informed decisions. For example, AI can predict customer behavior, demand fluctuations, or market shifts, enabling proactive decision-making.
- Data-Driven Recommendations: AI provides actionable insights and recommendations based on data analysis. These can help businesses identify opportunities, optimize processes, and improve outcomes across various departments such as marketing, operations, and customer service.
- Handling Large Datasets: AI is capable of processing large and complex datasets (big data) with ease, allowing businesses to scale their data analysis efforts without worrying about limitations in processing power or data size.
- Real-Time Analytics: AI can work with streaming data to provide continuous insights, allowing organizations to adapt quickly to changing conditions, such as market fluctuations, customer preferences, or operational issues.
- Reduced Human Error: AI agents can help reduce errors caused by human biases or fatigue, providing more reliable and consistent insights. They ensure that data analysis is objective and free from subjective influence.
- Improved Data Quality: AI systems can identify and correct anomalies, outliers, and inconsistencies in the data, ensuring that the insights drawn are based on high-quality and accurate information.
- Tailored Recommendations: AI can generate personalized insights for individual customers, segments, or business units. For example, AI can analyze customer data to create tailored marketing strategies, product recommendations, or personalized offers that increase engagement and conversions.
- Segmented Analysis: AI enables segmentation of data into meaningful groups, allowing businesses to target specific customer segments or operational areas more effectively.
- Uncovering Hidden Insights: AI agents excel at identifying complex patterns and relationships within data that might be missed by human analysts. This can lead to the discovery of new opportunities, risks, or market trends that were previously unknown.
- Anomaly Detection: AI can automatically detect outliers or anomalies in data, which is useful in identifying fraud, network intrusions, or quality issues before they become major problems.
- Reduced Operational Costs: By automating data analysis tasks, AI reduces the need for manual effort, which lowers labor costs. Moreover, AI can optimize processes, leading to cost savings in areas like supply chain management, resource allocation, and marketing.
- Efficient Resource Allocation: AI can provide insights that help organizations allocate resources more effectively, whether it’s staff, inventory, or marketing budgets, maximizing ROI.
- Forecasting Trends: AI agents use historical data to create predictive models that forecast future trends, such as customer demand, sales growth, or market conditions. This helps businesses plan more accurately and mitigate risks.
- Risk Identification: AI can identify potential risks by analyzing historical data and detecting patterns of behavior that may lead to undesirable outcomes, such as financial loss, reputational damage, or operational disruptions.
- Customer Sentiment Analysis: AI-powered sentiment analysis helps businesses gauge customer opinions and feedback from sources like social media, reviews, and surveys. This can guide product improvements, customer service strategies, and marketing efforts.
- Real-Time Customer Insights: AI can analyze customer behavior in real-time, enabling businesses to respond quickly to changing preferences or issues, thereby enhancing the customer experience.
- Self-Improvement: AI agents can continuously learn from new data, improving their performance and insights over time. This means that as more data becomes available, the AI system gets better at predicting, analyzing, and generating valuable insights.
- Adaptability: AI agents can adapt to changing business environments and evolving data patterns, ensuring that insights remain relevant and accurate even as circumstances change.
- Bias Detection: AI can help identify and reduce biases in data or decision-making processes. For example, AI can highlight instances where data may be skewed or where decision-making models might unintentionally favor one group over another.
- Compliance with Regulations: AI can also help organizations ensure compliance with data privacy laws and ethical standards by analyzing data usage patterns and flagging potential violations.
- Collaboration with Human Analysts: AI works alongside human experts, augmenting their capabilities rather than replacing them. While humans provide domain expertise and interpretability, AI offers speed, accuracy, and scalability in data processing and analysis.
- Integration with Business Systems: AI agents can seamlessly integrate with existing business systems, such as CRMs, ERPs, or marketing automation tools, providing insights that can be acted upon directly within these platforms.
AI agents bring substantial benefits to data-driven insights by enabling faster, more accurate, and scalable analysis. By automating repetitive tasks, uncovering hidden patterns, and providing actionable recommendations, AI empowers businesses to make smarter decisions, improve operational efficiency, and create more personalized customer experiences. The continuous learning capabilities of AI agents ensure that organizations can stay competitive in rapidly evolving markets, ultimately leading to increased innovation, cost savings, and enhanced performance.
How do Multi-Agents Help in Qualitative Data Analysis?Multi-agent systems play a crucial role in qualitative data analysis by enabling collaboration between multiple AI agents, each focusing on different aspects of the data. These agents work together to process, categorize, and interpret unstructured data, such as text, interviews, or survey responses. By leveraging natural language processing and sentiment analysis, multi-agent systems can identify key themes, extract meaningful insights, and detect patterns in large volumes of qualitative data.
Each agent can specialize in different tasks, such as text summarization, coding, or sentiment extraction, thereby enhancing the depth and accuracy of the analysis. As they interact and share findings, the agents can refine their models and produce a more comprehensive understanding of the data. This collaborative approach not only speeds up the analysis process but also helps to reduce human biases, improve consistency, and uncover nuanced insights, making it particularly valuable for researchers and businesses analyzing qualitative information at scale.
How to Build LLM-Based AI Agents for Data Analysis?Building Large Language Model (LLM)-based AI agents for data analysis involves using the power of large-scale pre-trained models (such as GPT-4, BERT, or similar LLMs) to handle tasks like natural language processing (NLP), generating insights from structured data, and automating data analysis tasks. These agents can analyze unstructured data (e.g., text, reports) and structured data (e.g., tables, databases), providing a wide range of use cases from summarization and trend analysis to making predictions and automating decision-making.
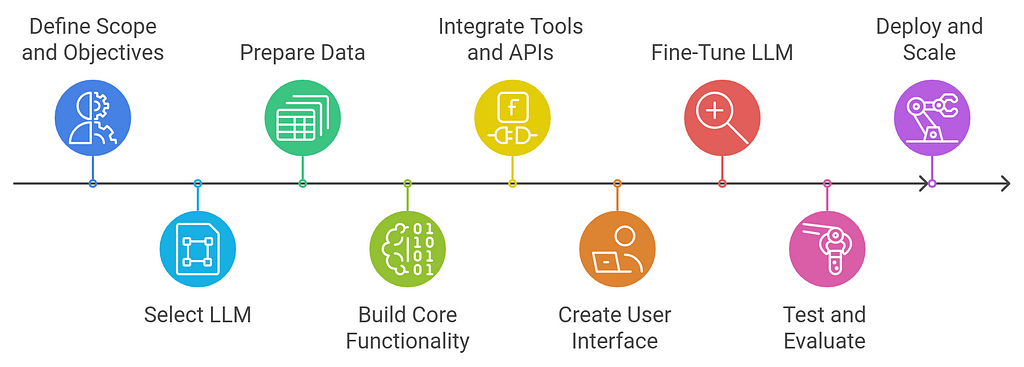
Here is a step-by-step guide on how to build LLM-based AI agents for data analysis:
1. Define the Scope and Objectives- Identify Tasks: Clearly define what specific data analysis tasks you want the AI agent to handle. These can include:
- Textual Data Analysis: Summarization, sentiment analysis, keyword extraction, or topic modeling.
- Prediction/Forecasting: Using historical data to predict future outcomes (e.g., sales forecasting, stock prediction).
- Data Cleaning and Transformation: Identifying missing data, outlier detection, or automating data preprocessing.
- Reporting and Insights Generation: Summarizing findings, generating reports, or creating data visualizations from analysis.
- Determine Inputs: Understand the types of data the agent will be analyzing (e.g., structured data like CSVs, or unstructured text data such as research papers, emails, etc.).
- Set Metrics for Success: Define how you’ll evaluate the agent’s effectiveness, such as accuracy, time to generate insights, or user satisfaction with automated reports.
- Pre-trained LLMs: Use existing pre-trained models like GPT-3, GPT-4, BERT, or T5 for general NLP tasks. These models have been trained on massive datasets and are adept at processing natural language and generating human-like responses.
- GPT-4 (Generative Pretrained Transformer 4): Well-suited for conversational AI, text generation, summarization, and advanced NLP tasks.
- BERT (Bidirectional Encoder Representations from Transformers): Good for tasks that require contextual understanding of text, such as text classification, question-answering, and information extraction.
- T5 (Text-to-Text Transfer Transformer): A versatile model that treats all NLP tasks as text generation problems, making it suitable for tasks like translation, summarization, and classification.
- Specialized Models: If you’re working with specific types of data (e.g., medical or financial), consider models fine-tuned for those domains.
- Data Collection: Gather the data that will be used for analysis. This could be structured data (e.g., databases, spreadsheets) or unstructured data (e.g., text, documents).
- Structured Data: Tables, CSVs, SQL databases, or time-series data.
- Unstructured Data: Text from various sources like reports, emails, news articles, or customer feedback.
- Structured Data: Clean the data by removing duplicates, handling missing values, encoding categorical variables, and normalizing numerical values.
- Unstructured Data: Perform text preprocessing, such as tokenization, stopword removal, stemming, and lemmatization.
- Data Transformation: If needed, transform the data into a format that is easier for LLMs to process. For example, converting raw text into sentences or documents that are more relevant for analysis.
- Text Classification: Use LLMs to classify documents into categories (e.g., sentiment analysis, topic categorization, or email classification).
- Named Entity Recognition (NER): Extract entities such as names, dates, organizations, etc., from text data.
- Summarization: Automatically summarize long documents or data reports to generate concise insights.
- Text Generation: Generate reports, conclusions, or hypotheses based on the data.
- Data Querying: Implement a natural language interface to query structured data. The agent should translate user queries in plain language into SQL queries to fetch relevant data.
- Predictive Modeling: Use LLMs to interpret structured data for making predictions, such as predicting customer churn or future sales based on historical data.
- Automating Insights Generation: Using LLMs, the agent can generate text-based insights or visualizations directly from the data (e.g., generating a summary report from financial data or a customer sentiment analysis from feedback).
- Recommendation Systems: If applicable, build a recommendation system that uses LLMs to provide suggestions based on patterns in the data (e.g., recommending similar products based on customer purchase history).
- Data Sources: Integrate with APIs or databases to fetch the data needed for analysis. For instance, using APIs to access real-time financial data or customer records.
- Business Intelligence (BI) Tools: If necessary, connect the AI agent to BI tools like Tableau, Power BI, or custom dashboards to visualize data insights or present findings in an interactive way.
- External Libraries: Use Python libraries like Pandas for data manipulation, Matplotlib or Seaborn for visualization, and Scikit-learn for traditional machine learning models if needed.
- Natural Language Interface: Design a conversational interface where users can ask questions in natural language. This could be a chatbot or a voice assistant that uses LLMs to understand and respond to user queries.
- Graphical Interface: If necessary, build a dashboard that allows users to input data and receive analysis results. This can include interactive charts, tables, and visualizations based on LLM-generated insights.
- Customization: Allow users to specify parameters for the analysis, such as time frames for forecasting or criteria for anomaly detection.
- Fine-Tuning with Domain-Specific Data: To improve the LLM’s performance, fine-tune it using domain-specific data (e.g., medical records, financial statements, or customer support tickets) to better understand the nuances of the data you’re analyzing.
- Transfer Learning: Leverage transfer learning to adapt the model to your specific dataset without needing to retrain it from scratch.
- Reinforcement Learning: If your agent is intended to continuously improve (such as in a dynamic business environment), use reinforcement learning to allow the model to adapt based on user feedback and real-world performance.
- Evaluate Accuracy: Test the agent’s performance on unseen data and evaluate metrics like accuracy, precision, recall, and F1 score for classification tasks, or RMSE for regression tasks.
- Test Edge Cases: Check how the agent handles edge cases or unusual inputs (e.g., ambiguous queries or missing data).
- Continuous Improvement: Collect feedback from users, track the agent’s performance over time, and iterate on the model to improve its accuracy and functionality.
- Deployment: Deploy the LLM-based agent on a cloud service or on-premise infrastructure depending on your needs. Consider using platforms like AWS, Google Cloud, or Azure for scalable deployments.
- Monitoring: Continuously monitor the agent’s performance to detect any issues or improvements that can be made. Track metrics such as response time, accuracy, and user engagement.
- Scalability: Ensure that the architecture is scalable to handle large amounts of data and user queries. Leverage cloud resources for processing power and storage as needed.
Building an LLM-based AI agent for data analysis involves combining the power of natural language processing with structured and unstructured data analysis techniques. By selecting the right LLM, preparing your data, and integrating the model into a user-friendly interface, you can create an intelligent system capable of automating data analysis tasks, generating actionable insights, and enabling more efficient decision-making. The key is continuous fine-tuning, evaluation, and scaling to improve accuracy and performance over time.
Use Cases of AI Agents in Data AnalysisAI agents are revolutionizing data analysis across industries, bringing automation, advanced analytics, and predictive capabilities to the forefront. Here are some key use cases where AI agents are playing a transformative role in data analysis:
 1. Predictive Analytics
1. Predictive Analytics- Sales Forecasting: AI agents analyze historical sales data to predict future sales trends, helping businesses forecast demand, plan inventory, and optimize supply chains.
- Customer Behavior Prediction: AI models can predict customer behavior, such as which products a customer is likely to buy next, based on their past interactions. This helps businesses tailor marketing strategies and personalize customer experiences.
- Churn Prediction: AI agents can analyze customer engagement data to predict which customers are at risk of churning, allowing companies to take proactive measures to retain them, such as offering discounts or personalized offers.
- Fraud Detection in Financial Transactions: AI agents can detect fraudulent transactions in real time by analyzing patterns and flagging unusual activities. For example, an AI system in banking might flag suspicious transactions that deviate from a user’s usual behavior.
- Quality Control in Manufacturing: AI can analyze data from production lines to identify anomalies, such as defective products or irregular patterns that may indicate equipment malfunctions or process failures.
- Network Security: In cybersecurity, AI can analyze network traffic to detect unusual patterns or potential security breaches, providing real-time alerts and enabling faster responses.
- Sentiment Analysis: AI agents use NLP to analyze customer feedback, reviews, or social media posts to gauge sentiment (positive, negative, or neutral). This helps businesses understand customer opinions, sentiment trends, and potential areas for improvement.
- Topic Modeling: AI can analyze large volumes of text (such as customer support tickets, emails, or articles) to identify common themes and topics, making it easier for organizations to understand trends and focus on the most pressing issues.
- Automated Document Classification: AI agents can automatically categorize documents, emails, and contracts based on their content. For example, in legal industries, AI can categorize documents based on legal topics or urgency, streamlining document management.
- E-commerce Recommendations: AI analyzes customer browsing and purchase history to provide personalized product recommendations, boosting sales and improving the shopping experience. For instance, AI in platforms like Amazon suggests items based on a user’s previous activity.
- Content Personalization: AI agents help tailor content delivery by analyzing user preferences and behavior. In media streaming services like Netflix or Spotify, AI suggests movies, shows, or music based on user history and similar preferences.
- Dynamic Pricing: AI can analyze market conditions, customer behavior, and competitor pricing to dynamically adjust prices, ensuring that businesses remain competitive while maximizing profits.
- Targeted Marketing: AI can segment customers based on demographic, behavioral, and transactional data, allowing businesses to craft highly targeted marketing campaigns. For instance, AI can group customers who are likely to respond to specific types of offers.
- Customer Lifetime Value (CLV) Prediction: By analyzing past customer behavior and transaction history, AI agents predict the long-term value of customers, allowing businesses to focus on high-value customers and improve retention strategies.
- Stock Market Predictions: AI agents analyze historical stock price data and market trends to forecast future market movements, aiding traders and investors in making more informed decisions.
- Demand Forecasting: Retailers and manufacturers use AI to predict product demand over time, helping them optimize stock levels and prevent overstocking or stockouts. AI can analyze seasonal trends and external factors (such as holidays or economic changes) to generate more accurate forecasts.
- Energy Consumption Optimization: AI analyzes past energy usage patterns to predict future demand and optimize energy distribution, helping utilities reduce waste and improve efficiency.
- Real-Time Dashboards: AI can automatically generate real-time dashboards and reports based on live data. For instance, in finance, AI can provide real-time insights into portfolio performance, market movements, and financial metrics.
- Data Summarization: AI agents can extract key insights from large datasets and generate easy-to-understand summaries, allowing decision-makers to quickly grasp the most important findings without delving into complex details.
- Inventory Management: AI agents analyze sales, inventory, and supplier data to optimize inventory levels, helping businesses reduce costs associated with overstocking or stockouts.
- Route Optimization: In logistics and delivery, AI agents analyze data such as traffic conditions, delivery times, and weather to optimize delivery routes and schedules, improving efficiency and reducing fuel costs.
- Demand Forecasting: AI can predict shifts in demand for products, allowing businesses to adjust their supply chains accordingly, ensuring that products are available when needed while avoiding excess stock.
- Talent Acquisition: AI agents analyze resumes and job applications to identify the most qualified candidates, automating the hiring process and improving recruitment efficiency. AI can also assess candidates based on factors like experience, skills, and cultural fit.
- Employee Sentiment Analysis: AI can analyze employee feedback, surveys, and social media posts to gauge overall employee sentiment, identify areas of concern, and improve workplace culture.
- Performance Management: AI can track employee performance data and help managers identify patterns in productivity, enabling data-driven decisions about promotions, raises, and professional development.
- Medical Diagnosis: AI agents can analyze patient data, such as medical histories, lab results, and imaging data, to assist doctors in diagnosing conditions, detecting early signs of diseases, and recommending treatment options.
- Personalized Treatment Plans: AI can help create personalized healthcare plans by analyzing patient data and predicting how different treatments may affect specific individuals, improving outcomes in precision medicine.
- Healthcare Predictive Analytics: AI models predict patient health trends, such as the likelihood of hospital readmission or the progression of chronic conditions, enabling preventive measures and better resource allocation in healthcare facilities.
- Property Valuation: AI agents analyze market trends, property features, and external factors to provide accurate property valuations and investment advice. For example, they can predict property appreciation over time based on historical trends and regional economic factors.
- Real Estate Investment Analysis: AI helps investors assess the risk and potential return of real estate investments by analyzing historical property data, market conditions, and financial variables.
- Automated Data Insights: AI systems generate automated insights and reports based on pre-defined business questions, reducing the need for manual data analysis and report generation. This is particularly useful in industries like finance, marketing, and healthcare, where timely reporting is critical.
AI agents are transforming data analysis across various domains by enabling faster, more accurate, and actionable insights. From predictive analytics and customer behavior analysis to fraud detection and real-time reporting, AI plays a critical role in helping businesses make data-driven decisions that enhance efficiency, profitability, and customer satisfaction. With the ability to process large datasets, uncover hidden patterns, and provide personalized recommendations, AI agents are essential tools for modern data analysis.
Overcoming Challenges in Implementing AI Agents for Data AnalysisImplementing AI agents for data analysis presents significant opportunities but also several challenges. Overcoming these challenges requires careful planning, investment in resources, and strategic alignment between technology and business goals. Below are the key challenges faced when implementing AI agents in data analysis and strategies to overcome them:
 1. Data Quality and Availability
1. Data Quality and Availability- Challenge: AI systems rely heavily on high-quality, well-structured data. In many cases, businesses face issues with incomplete, inconsistent, or noisy data, which can undermine the performance of AI models.
- Data Cleaning and Preprocessing: Implement data wrangling tools and processes to clean, normalize, and structure data before feeding it into AI models.
- Data Integration: Use data integration platforms to consolidate data from disparate sources, ensuring that AI agents have access to comprehensive datasets.
- Data Governance: Establish a robust data governance framework that ensures data accuracy, consistency, and security throughout the organization.
- Challenge: Building and maintaining AI systems for data analysis requires a team of skilled professionals, including data scientists, machine learning engineers, and domain experts. There’s often a shortage of professionals with the required expertise.
- Upskilling and Training: Invest in training programs for existing staff to build their capabilities in AI, data science, and machine learning. Online courses, workshops, and certifications can help bridge the talent gap.
- Collaborations with AI Experts: Partner with AI consultants or third-party vendors to fill the knowledge gap while building internal expertise over time.
- Low-Code/No-Code AI Tools: Leverage low-code or no-code AI platforms that allow business analysts and non-technical users to build and implement AI models, reducing the reliance on specialized talent.
- Challenge: AI models can inherit biases present in the data they are trained on, leading to inaccurate or discriminatory outcomes. This is a major concern, especially in sensitive areas such as hiring, lending, or healthcare.
- Bias Detection and Mitigation: Implement strategies to detect and mitigate bias in data and models. Techniques such as adversarial training, re-weighting data, and using fairness constraints during model training can reduce bias.
- Diverse Data Sources: Ensure that training data comes from diverse and representative sources to avoid biased outcomes, particularly when the data is related to demographics, geography, or socioeconomic factors.
- Regular Audits: Conduct regular audits of AI models to check for unintended bias and retrain models as necessary to improve fairness.
- Challenge: Developing AI models that accurately reflect business problems and produce actionable insights can be complex. It requires a deep understanding of both the data and the domain in which the AI is being applied.
- Collaborative Approach: Foster collaboration between data scientists, domain experts, and business leaders to ensure AI models align with the organization’s objectives and deliver relevant insights.
- Incremental Model Building: Start with simpler models and iteratively improve them over time. This allows organizations to build on initial success while continuously refining the AI models.
- Use of Pretrained Models: Leverage pretrained AI models or frameworks (such as GPT, BERT, or other domain-specific models) that can be fine-tuned for specific tasks, reducing the complexity of building models from scratch.
- Challenge: Integrating AI agents into legacy systems and existing workflows can be difficult, especially if those systems were not designed with AI in mind. AI implementation often requires significant changes to IT infrastructure.
- Modular Integration: Start by integrating AI agents with smaller, modular parts of existing systems to minimize disruption and test the technology in controlled environments.
- Cloud Platforms and APIs: Use cloud-based AI solutions that offer flexible integration options through APIs and services, reducing the complexity of system integration.
- Hybrid Approaches: Implement hybrid models that combine AI with traditional data analysis methods, ensuring a smooth transition while gradually increasing reliance on AI agents.
- Challenge: Implementing AI-driven data analysis can be costly, particularly for small to medium-sized businesses. Costs include purchasing or developing AI software, hiring experts, and investing in infrastructure.
- Cloud-Based Solutions: Use cloud-based AI solutions and platforms, which offer pay-as-you-go models, reducing the initial investment and operational costs. Cloud platforms also provide scalability and access to high-performance computing resources.
- Pilot Projects: Start with pilot projects to test AI’s feasibility and value before scaling. This allows organizations to assess the ROI of AI without committing to large upfront investments.
- Open Source Tools: Leverage open-source AI tools and libraries (such as TensorFlow, Scikit-learn, or Apache Spark) to minimize software costs. Open-source tools can be customized to meet specific business needs without the hefty price tag of proprietary software.
- Challenge: AI systems often require access to sensitive data, which raises concerns about data privacy and security. Compliance with regulations like GDPR, HIPAA, or CCPA is crucial, and breaches can lead to significant financial and reputational damage.
- Privacy-Preserving AI: Implement privacy-preserving AI techniques, such as federated learning or differential privacy, which allow AI models to be trained on sensitive data without exposing the raw data itself.
- Data Encryption and Secure Access: Use strong encryption methods to secure data at rest and in transit. Additionally, ensure that access to sensitive data is tightly controlled with proper authentication and authorization mechanisms.
- Compliance and Audits: Ensure that AI systems comply with relevant data protection regulations and conduct regular security audits to identify vulnerabilities.
- Challenge: Many AI models, especially deep learning models, operate as “black boxes,” making it difficult to understand how they arrive at specific decisions. This lack of transparency can hinder trust and adoption, especially in regulated industries.
- Explainable AI (XAI): Invest in explainable AI techniques that make AI models more transparent and interpretable. Tools like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-Agnostic Explanations) can help explain model predictions.
- Model Auditing: Regularly audit AI models to ensure they are making fair, unbiased, and understandable decisions. Provide clear documentation on how models work, how they were trained, and how their decisions can be explained.
- User-Friendly Interfaces: Build user-friendly dashboards and reporting tools that allow business users to understand and interpret AI-generated insights easily.
- Challenge: Employees may resist the adoption of AI agents due to concerns about job displacement, unfamiliarity with new technology, or a lack of trust in automated decision-making systems.
- Change Management: Implement change management strategies that include clear communication, training, and support to help employees adapt to AI-driven workflows. Emphasize that AI is a tool to augment human decision-making, not replace it.
- AI as an Assistant: Position AI as an assistant rather than a replacement. AI can help employees by automating routine tasks, allowing them to focus on higher-value, more creative work.
- Pilot Programs: Launch pilot programs that demonstrate the value and effectiveness of AI agents, showing employees how AI can enhance their work and improve outcomes.
While the implementation of AI agents for data analysis offers immense potential, overcoming these challenges requires careful planning, investment in resources, and collaboration across technical, business, and regulatory teams. By focusing on data quality, talent development, model transparency, cost management, and integration with existing systems, organizations can successfully harness the power of AI to unlock valuable insights and drive innovation.
The Future of AI Agents in Data AnalysisThe future of AI agents in data analysis looks incredibly promising, as advancements in artificial intelligence, machine learning, and data processing continue to accelerate. AI agents are poised to transform how businesses, governments, and organizations analyze data, extract insights, and make decisions. Here’s a look at some key trends and innovations shaping the future of AI agents in data analysis:
 1. Increased Automation in Data Processing
1. Increased Automation in Data Processing- Automation of Routine Tasks: In the future, AI agents will automate more complex data processing tasks such as data cleaning, data integration, and anomaly detection. This will allow data scientists and analysts to focus on higher-level strategy and interpretation, rather than spending time on manual tasks.
- End-to-End Automation: We may see AI systems capable of performing end-to-end data workflows, from data collection and cleaning to analysis and visualization, with minimal human intervention. This will significantly speed up the time to insight and reduce human error.
- Predictive Analytics: AI agents will become even more adept at predicting future outcomes with greater accuracy. They will analyze large datasets across different variables and use advanced algorithms to forecast trends, demand, market behavior, and even potential risks.
- Prescriptive Analytics: Moving beyond prediction, future AI agents will be able to provide actionable recommendations (prescriptive analytics) to optimize decision-making. For example, they could recommend the best course of action to mitigate risks, optimize marketing strategies, or improve operational efficiency based on real-time data.
- Conversational Analytics: As NLP capabilities improve, AI agents will allow users to interact with data through natural language queries. Users could simply ask questions like “What were the key sales drivers last quarter?” or “How will customer demand change in the next three months?” and AI agents will generate answers instantly.
- Text and Sentiment Analysis: AI agents will increasingly analyze unstructured data, such as social media posts, customer reviews, and emails, to gain deeper insights into customer sentiment, market trends, and brand perception, offering businesses a more holistic view of their environment.
- Explainable AI (XAI): As AI continues to be used for critical decision-making, ensuring that models are explainable will be essential. The future will see AI agents incorporating more transparent decision-making processes, allowing business users to understand how AI models arrive at their conclusions. This will improve trust in AI systems and ensure compliance with regulatory standards.
- Human-in-the-Loop Models: AI agents will continue to evolve in a way that combines human expertise with AI-driven insights. Rather than replacing humans, AI will assist them by offering suggestions, explanations, and predictions that can be interpreted and validated by human decision-makers.
- Real-Time Analytics: AI agents will be able to process and analyze real-time data streams more effectively, providing businesses with immediate insights into current conditions. For example, AI can detect shifts in customer behavior during a product launch or identify emerging security threats in real time.
- Edge AI: With the proliferation of Internet of Things (IoT) devices, edge AI will become more prominent. AI agents will process data locally on devices (edge computing) instead of sending it to the cloud, enabling faster analysis and decisions with minimal latency.
- Immersive Data Visualization: Future AI agents will work in tandem with augmented and virtual reality to deliver immersive data visualizations. This can help users interact with data in 3D environments, where they can explore trends, correlations, and insights more intuitively and engagingly.
- AI-Driven Virtual Assistants: In combination with AR/VR, AI agents could act as virtual assistants, guiding users through complex datasets or helping in training scenarios where immersive, real-time data interaction is key.
- Bias Mitigation: As AI becomes more integrated into decision-making processes, ensuring that models are ethical and unbiased will be crucial. Future AI agents will come with built-in mechanisms to detect and reduce bias in datasets and decision models, promoting fairness in areas such as hiring, lending, and law enforcement.
- Ethical AI Frameworks: Companies and governments will adopt AI governance frameworks to ensure ethical use of AI agents in data analysis. AI systems will be designed to adhere to ethical standards, ensuring transparency, fairness, and accountability in automated decisions.
- AI-Assisted Decision-Making: The future of AI agents in data analysis will be less about replacing human analysts and more about augmenting their capabilities. AI will become a trusted advisor, offering data-driven insights that human experts can validate, refine, and act upon.
- Human-AI Collaboration: AI agents will serve as collaborative tools, providing insights, recommendations, and predictive analytics while humans focus on high-level decision-making, creativity, and strategy. This will foster a new era of human-AI partnership in the workplace.
- Customized Reporting: AI agents will tailor data analysis and reporting to individual preferences, making it easier for stakeholders to consume relevant insights. For example, AI could personalize dashboards, reports, and alerts based on the user’s role, preferences, or objectives.
- Adaptive AI Models: AI agents will adapt over time to the changing preferences and needs of users, continuously improving the relevance and accuracy of insights by learning from past interactions and outcomes.
- Healthcare: In healthcare, AI agents will help doctors analyze patient data, predict disease progression, and recommend personalized treatment plans based on patient histories and medical research. AI will also help streamline administrative processes like billing, coding, and claims.
- Finance: In finance, AI agents will provide better risk analysis, fraud detection, and portfolio management. Predictive models will enable financial institutions to make more informed investment decisions and assess market conditions in real time.
- Manufacturing and Supply Chain: AI agents will optimize supply chains by analyzing demand patterns, managing inventory, and predicting equipment maintenance needs. AI will also play a key role in quality control and process optimization in manufacturing industries.
- Cloud-Based AI: AIaaS platforms will enable organizations of all sizes to access powerful AI capabilities without requiring in-house expertise or infrastructure. This will democratize access to advanced data analysis tools, allowing businesses to implement AI-driven data analysis with minimal upfront investment.
- Plug-and-Play AI Models: The future will see the rise of pre-trained AI models that can be easily customized and deployed across various industries. These models will allow businesses to start using AI-driven insights quickly, without having to train models from scratch.
- Environmental Impact: As the computational power needed for AI increases, there will be a push for more energy-efficient AI models and processes. The future of AI agents in data analysis will focus on reducing the carbon footprint of AI systems while maintaining performance.
- Sustainability Insights: AI will also be used to analyze data related to environmental sustainability, helping businesses and governments identify ways to reduce waste, carbon emissions, and environmental impact through data-driven strategies.
The future of AI agents in data analysis is bright, with advancements leading to smarter, more efficient, and transparent systems. AI will not only automate data processing but will also provide predictive insights, drive more personalized customer experiences, and enable real-time decision-making. As AI continues to evolve, it will empower businesses to make data-driven decisions faster and more accurately, while creating opportunities for collaboration between human expertise and artificial intelligence. However, as AI becomes a more integral part of decision-making processes, ensuring ethical practices, transparency, and privacy will be crucial to gaining trust and maximizing its benefits.
ConclusionIn conclusion, AI agents have become an essential tool in modern data analysis, offering unprecedented capabilities to process and interpret large volumes of data. By automating complex tasks and providing deep, actionable insights, AI-driven systems empower organizations to make more informed, data-backed decisions with greater speed and accuracy. As industries continue to generate massive amounts of data, AI agents will only become more integral, enabling businesses to unlock hidden patterns, improve efficiency, and drive innovation.
From predictive analytics to anomaly detection, the applications of AI in data analysis are vast and transformative, providing a competitive advantage in an increasingly data-driven world. Embracing AI technologies not only streamlines the analytical process but also enhances decision-making, creating new opportunities for growth and success.
As this technology evolves, the potential for even more advanced and tailored AI solutions will continue to reshape how organizations utilize data. For those looking to stay ahead of the curve, leveraging AI agents in data analysis is no longer a choice but a strategic necessity for long-term success.
FAQs1. What are AI agents in data analysis?AI agents in data analysis are software tools that leverage artificial intelligence, such as machine learning, natural language processing (NLP), and deep learning, to autonomously process, analyze, and interpret data. These agents help identify patterns, generate insights, automate decision-making, and predict future trends based on data.
2. How do AI agents help in data analysis?AI agents assist in data analysis by automating tasks such as data preprocessing, cleaning, feature extraction, and pattern recognition. They also provide predictive analytics, anomaly detection, and text or sentiment analysis. By reducing the time spent on manual analysis, they enhance efficiency and improve decision-making.
3. What types of data can AI agents analyze?AI agents can analyze both structured data (like tables, spreadsheets, and databases) and unstructured data (such as text, images, and audio). They are particularly effective in processing large datasets, performing complex analyses, and deriving insights that would be time-consuming for humans to extract.
4. What are the benefits of using AI agents for data analysis?- Efficiency: AI agents can process vast amounts of data quickly, automating tasks that would typically require significant human resources.
- Accuracy: They reduce human error in data analysis and provide more reliable, data-driven insights.
- Scalability: AI agents can scale to handle large datasets and complex problems without the need for additional human intervention.
- Cost-Effective: Automation reduces the need for manual labor, leading to lower operational costs.
- Real-time Analysis: AI agents can provide real-time data analysis and generate immediate insights.
- Predictive Analytics: AI agents can forecast trends such as sales, customer behavior, or financial performance.
- Customer Insights: By analyzing customer data, AI agents can help businesses understand customer preferences, segmentation, and improve targeting.
- Anomaly Detection: AI agents can identify unusual patterns in data, such as fraud detection in financial transactions or network security breaches.
- Text Analytics: AI agents can process and analyze large volumes of text data, generating insights from reviews, social media, or reports.
- Market Research: AI agents help businesses stay ahead of market trends by analyzing competitor data and consumer sentiment.
AI agents use a variety of machine learning models, including:
- Supervised Learning: Used for classification and regression tasks with labeled data.
- Unsupervised Learning: Used for clustering, anomaly detection, and dimensionality reduction with unlabeled data.
- Reinforcement Learning: Employed in tasks where agents learn through trial and error, optimizing decisions based on rewards.
- Deep Learning: Used for more complex data, such as images, audio, or natural language processing.
- Natural Language Processing (NLP): Used for analyzing and understanding textual data.
Data preprocessing is a crucial step in AI-driven data analysis because it involves cleaning and transforming raw data into a format suitable for modeling. This step includes tasks such as:
- Handling missing or inconsistent data
- Normalizing and scaling numerical data
- Encoding categorical variables
- Tokenizing and vectorizing text data Proper preprocessing ensures the AI agent performs optimally and produces accurate results.
AI agents can provide data-driven insights that help businesses make informed decisions. For example:
- Risk Assessment: By analyzing historical data, AI agents can predict future risks or opportunities.
- Optimizing Operations: AI agents can identify inefficiencies in business processes and recommend improvements.
- Personalization: AI agents can analyze customer behavior and preferences to personalize recommendations, improving customer satisfaction and increasing sales.
- Data Quality: Poor-quality data can lead to inaccurate insights. Ensuring data is clean, relevant, and complete is essential.
- Complexity: Setting up AI agents, especially for complex tasks, may require advanced expertise in machine learning and data science.
- Cost: Developing and deploying AI agents can be expensive, especially for small businesses.
- Data Privacy: Ensuring compliance with data protection laws (such as GDPR) and safeguarding sensitive information is crucial when using AI for data analysis.
- Integration: Integrating AI agents with existing systems and workflows can be a challenge, particularly for legacy systems.
AI agents learn from data using machine learning algorithms. In supervised learning, they are trained on labeled data (data with known outcomes) to make predictions or classifications. In unsupervised learning, they find patterns and structure in unlabeled data. The agent improves through iterative learning processes, adjusting its model based on feedback (e.g., in reinforcement learning) or by optimizing model parameters to minimize error.
AI Agents In Data Analysis: The Ultimate Guide to Data-Driven Insights was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.