How Can You Create a Scalable AIOps Platform Solution in 2025?
Building a robust private Large Language Model (LLM) for real-time applications requires a careful approach to ensure scalability, security, and high performance. First, it’s essential to choose the right infrastructure, including powerful hardware and efficient cloud solutions, to handle the demands of real-time processing. Privacy and data security are critical, so implementing encryption protocols and ensuring that sensitive information is handled responsibly is key.

Additionally, training the LLM on a diverse, high-quality dataset that reflects the specific needs of the application will improve its accuracy and relevance. Fine-tuning the model for real-time performance is crucial to ensure low latency and high throughput, especially for time-sensitive tasks. Optimizing the model’s architecture and using techniques such as model pruning and quantization can further enhance efficiency.
Finally, regular monitoring and updates are vital for maintaining the model’s effectiveness as new data and technologies emerge. By following these best practices, businesses can create a private LLM that provides reliable, secure, and seamless real-time experiences for their users.
What is Private LLM Development?Private LLM development refers to the process of creating and deploying a Large Language Model (LLM) that is tailored for private, secure, and specific use cases. Unlike public models, which are hosted and operated by third-party providers, private LLMs are developed and maintained within an organization’s own infrastructure or controlled environment. This ensures better data privacy, security, and control over how the model is trained, fine-tuned, and applied. Private LLMs are designed to handle sensitive information without compromising confidentiality, making them ideal for industries such as healthcare, finance, and legal services..
The development of a private LLM development involves selecting appropriate datasets, training the model to meet specific business needs, and implementing robust security measures to protect against data breaches. Additionally, optimizing the model for real-time applications, scalability, and low latency is crucial for ensuring its performance in fast-paced environments. Private LLM development enables businesses to leverage the power of advanced AI while maintaining control over their data and intellectual property.
Key Considerations Before Building a Private LLMBuilding a private Large Language Model (LLM) can offer significant benefits, such as enhanced control over data, customization, and security. However, there are several key considerations to take into account before embarking on this complex and resource-intensive project. Below are the crucial factors to evaluate:
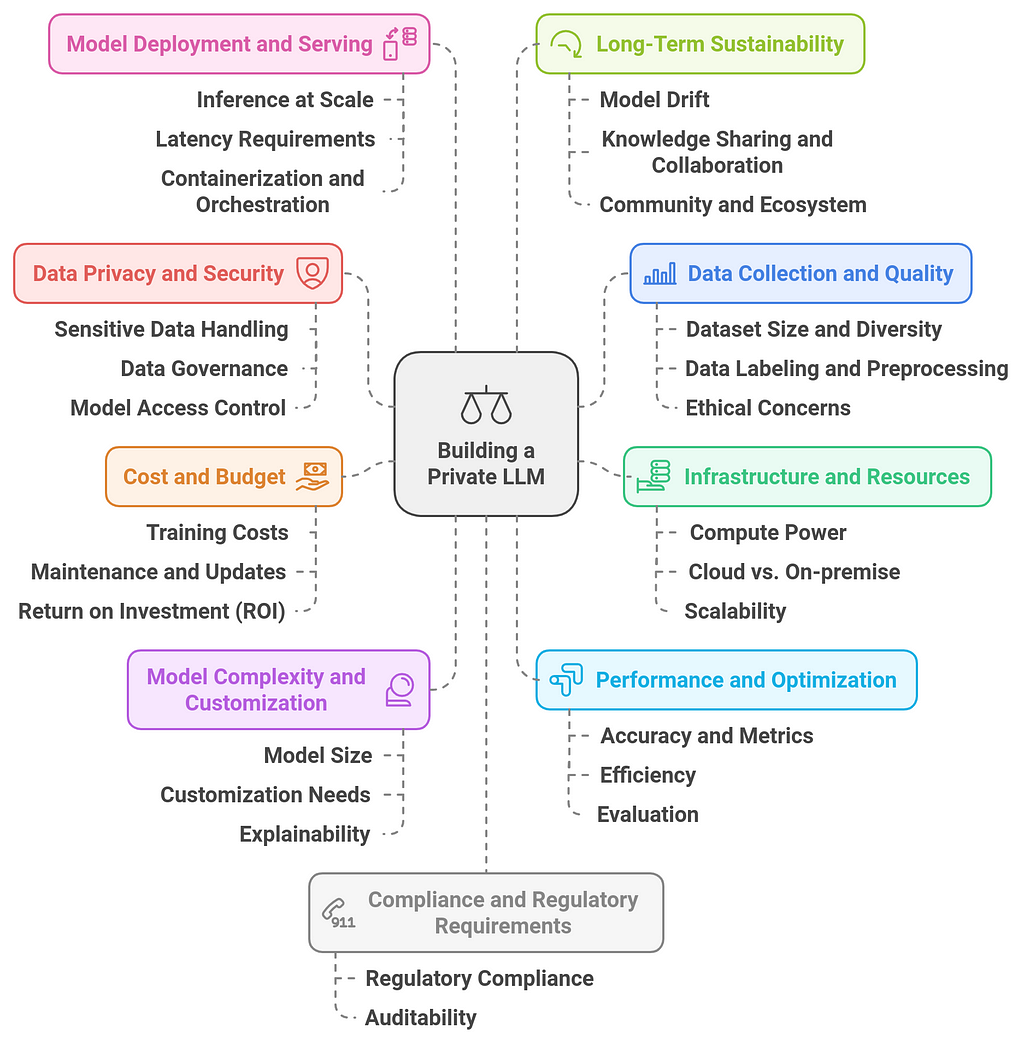 1. Data Privacy and Security
1. Data Privacy and Security- Sensitive Data Handling: Ensure that your model complies with data privacy regulations like GDPR, HIPAA, or CCPA. Protecting user data and maintaining confidentiality is critical, especially when dealing with sensitive information like healthcare data, financial records, or personal identifiers.
- Data Governance: Establish clear guidelines on data collection, usage, retention, and disposal. You’ll need robust security measures to prevent data leaks and unauthorized access.
- Model Access Control: Define who will have access to the model, both during development and in production. Implement role-based access controls and secure APIs to ensure only authorized users can interact with the model.
- Dataset Size and Diversity: To build a robust LLM, you’ll need access to large and diverse datasets relevant to your domain. Evaluate the availability and quality of the data you plan to use. The more diverse and representative your dataset, the better the model will perform across different scenarios.
- Data Labeling and Preprocessing: Consider the need for labeled data, especially if you’re focusing on supervised learning. Data preprocessing (e.g., tokenization, normalization) and cleaning will be essential for high-quality training.
- Ethical Concerns: Be aware of potential biases in the training data. Biases can manifest in various forms, such as gender, race, or geographic biases, which could affect the model’s performance and fairness. Bias mitigation strategies should be incorporated from the outset.
- Compute Power: Training an LLM from scratch or fine-tuning a large pre-trained model requires substantial computational resources. Assess whether you have access to the necessary infrastructure, such as powerful GPUs/TPUs, large-scale storage, and networking capabilities.
- Cloud vs. On-premise: Decide whether to use cloud-based services (AWS, Google Cloud, Azure) or on-premise infrastructure. Cloud platforms offer flexibility and scalability, but on-premise setups provide more control over your resources and data.
- Scalability: Consider future scalability needs, particularly if you anticipate handling larger datasets or deploying the model in production across multiple environments. Make sure your infrastructure can scale efficiently without excessive overhead.
- Training Costs: The cost of training a large model can be significant. Estimate the cost of compute resources, storage, and associated services for data collection and preprocessing. Training a model from scratch can be far more expensive than fine-tuning an existing pre-trained model.
- Maintenance and Updates: Ongoing maintenance costs should also be factored in. This includes retraining the model with new data, addressing model drift, and performing regular updates to improve performance.
- Return on Investment (ROI): Consider the long-term ROI. Will building a private LLM save costs or provide business advantages that justify the initial investment? The ability to customize a model for your specific use case may offer significant value, but it should align with business goals.
- Model Size: Consider the trade-off between model performance and computational overhead. Large models (billions of parameters) tend to perform better but require more resources for training and inference. Depending on your needs, you might choose to fine-tune an existing model or train a smaller one from scratch.
- Customization Needs: Define the level of customization required. Will the model need to be tailored to a specific domain (e.g., legal, healthcare, finance), or will it be a more general-purpose model? Fine-tuning a pre-trained model on domain-specific data is usually more efficient and cost-effective than training from scratch.
- Explainability: If your model will be used in sensitive areas (e.g., healthcare, finance), consider how explainable the model needs to be. Many large models are “black boxes,” which can complicate troubleshooting and compliance with regulations that require transparency.
- Accuracy and Metrics: Define the performance metrics that matter most for your application (e.g., accuracy, F1 score, perplexity, etc.). Assess whether your data and resources are sufficient to achieve the desired level of performance.
- Efficiency: Large LLMs can be slow and resource-intensive, especially during inference. Consider implementing techniques like model quantization, pruning, or distillation to optimize performance and reduce latency without sacrificing too much accuracy.
- Evaluation: Regularly evaluate the model against validation and test datasets to ensure it generalizes well to unseen data. Overfitting is a common issue when training large models on limited datasets.
- Inference at Scale: Consider how the model will be deployed and served. You’ll need to set up an inference pipeline that can handle real-time requests at scale, possibly in a microservices architecture.
- Latency Requirements: If the model is expected to provide real-time responses (e.g., in customer support or search), latency will be an important factor. Optimize the model and infrastructure to ensure fast response times.
- Containerization and Orchestration: Use containerization (e.g., Docker) and orchestration tools (e.g., Kubernetes) for scalable and maintainable deployment of the model in production environments.
- Regulatory Compliance: Ensure that the model and the processes involved in data collection and model deployment comply with industry regulations (e.g., GDPR, HIPAA, CCPA). This includes handling personal data, providing transparency on how the model works, and ensuring user consent when required.
- Auditability: The ability to audit model decisions and track changes to the model is increasingly important, especially in industries like finance, healthcare, and law. Implementing systems for logging and tracking model interactions can help in compliance and accountability.
- Bias and Fairness: Consider the potential ethical implications of building an LLM. Bias in training data can lead to biased predictions, and there may be fairness concerns if the model perpetuates harmful stereotypes or makes unfair decisions.
- Accountability: Ensure that there are mechanisms in place for accountability, particularly if the LLM is used in decision-making processes that impact individuals’ lives, such as in hiring, lending, or criminal justice.
- Model Drift: Over time, the model may become outdated as language, trends, or domains evolve. Plan for model updates and retraining to ensure continued accuracy and relevance.
- Knowledge Sharing and Collaboration: Building and maintaining a private LLM requires a high level of expertise. Consider the ongoing need for skilled personnel in AI/ML, as well as potential collaborations with research institutions or other organizations.
- Community and Ecosystem: Stay informed about advancements in the AI and machine learning community. New techniques, models, and tools may emerge that could improve your model’s performance, efficiency, or usability.
Building a private LLM requires careful consideration of multiple factors, including data privacy, infrastructure, costs, performance, compliance, and ethical implications. Understanding these key considerations upfront will help you make informed decisions that balance the technical, business, and regulatory requirements of your project. Whether you’re customizing a pre-trained model or building from scratch, ensure that your approach aligns with your organization’s goals, budget, and long-term strategy.
Steps to Build a Private LLM for Real-Time ApplicationsBuilding a private Large Language Model (LLM) for real-time applications requires a systematic approach to ensure that the model is both effective and efficient for production use. Below are the essential steps to building a private LLM tailored for real-time applications:
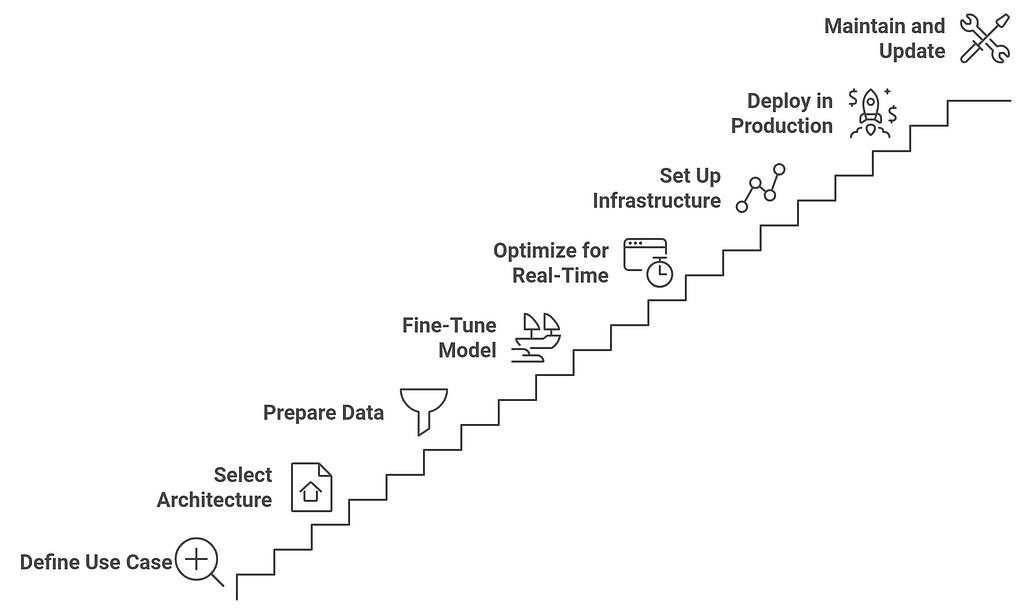 1. Define the Use Case and Requirements
1. Define the Use Case and Requirements- Objective Identification: Clearly define the specific use case (e.g., customer support, personalized recommendations, medical analysis) to ensure the model addresses the right problem.
- Performance and Latency: Determine the required performance (accuracy, relevance) and latency (response time) expectations for real-time applications.
- Data Requirements: Identify the types and sources of data you will need, including text, images, or structured data. This will also help in defining your training and evaluation metrics.
- Model Type: Choose between training a model from scratch or fine-tuning an existing pre-trained model. Fine-tuning a pre-trained model (e.g., GPT-3, BERT, T5) is often more cost-effective and quicker than training from scratch.
- Model Size: Choose an appropriate model size based on your application’s resource constraints and required accuracy. Large models like GPT-3 may provide high accuracy but are slower and more resource-intensive. Consider smaller, more efficient architectures like distilled models or fine-tuned BERT models for low-latency use cases.
- Pre-trained Models: Explore available open-source models (Hugging Face Transformers, OpenAI GPT, etc.) to start with, and check if they meet your needs or need to be further customized.
- Data Collection: Gather large amounts of text data related to your application. This data can be scraped, collected from internal sources, or purchased from third-party providers.
- Data Cleaning: Clean the data to remove noise, inconsistencies, and irrelevant information. Tokenization, stemming, and removing stop words are crucial preprocessing steps.
- Data Labeling: If your application requires supervised learning, you will need labeled data. Use human annotators or semi-automated systems to label data relevant to your domain (e.g., customer inquiries, medical conditions).
- Data Augmentation: For certain real-time applications, augmenting data to cover a broader range of input scenarios (e.g., paraphrasing, translations) can improve model robustness.
- Fine-Tuning: Once a base model is selected, fine-tune it on your specific domain’s dataset. Fine-tuning helps the model specialize in understanding domain-specific terminology, language, and context.
- Optimization: Implement techniques such as learning rate scheduling, gradient clipping, and data augmentation to improve fine-tuning results.
- Overfitting Prevention: Monitor for overfitting, especially with real-time data, to ensure that the model generalizes well to new, unseen input.
- Model Pruning: Apply model pruning techniques to reduce the size of the model by eliminating redundant parameters. This can help with reducing response time and computational load in real-time applications.
- Quantization: Use techniques like quantization (reducing precision) to reduce the model size and improve inference speed without losing much accuracy.
- Distillation: Model distillation involves creating a smaller “student” model that mimics the behavior of the large “teacher” model. This smaller model can perform inference much faster, suitable for real-time applications.
- Edge Deployment: If low-latency and offline capabilities are needed, consider deploying the model to edge devices. Model size reduction techniques like quantization and pruning are essential for edge deployments.
- Infrastructure Design: Set up scalable cloud infrastructure (AWS, GCP, Azure) or on-premise hardware (e.g., GPUs, TPUs) for running the model in production. Ensure you have enough compute power to handle the volume of real-time requests.
- Low-Latency APIs: Build APIs using frameworks like TensorFlow Serving, FastAPI, or Hugging Face Inference API. These should allow for high-performance and low-latency querying of the model.
- Caching: Implement a caching system for frequent or repetitive queries to minimize latency and optimize performance.
- Containerization: Containerize your model using Docker to ensure consistent deployment across different environments. This will make it easier to scale and maintain the system.
- Continuous Integration/Continuous Deployment (CI/CD): Set up CI/CD pipelines to automate model updates, monitor performance, and ensure smooth deployments without downtime.
- Model Monitoring: Continuously monitor the model in production to detect any degradation in performance, biases, or errors. Use tools like Prometheus, Grafana, or Datadog for real-time metrics tracking.
- Auto-Scaling: Implement auto-scaling in cloud environments to handle sudden spikes in demand. This will ensure that the model can serve requests without delay under heavy traffic conditions.
- Load Balancing: Set up load balancers to distribute traffic evenly across model instances to ensure high availability and fault tolerance.
- Redundancy: Deploy multiple replicas of your model across different servers or regions to ensure high availability and minimize single points of failure.
- Cost Management: Monitor the costs associated with the compute and storage resources required for real-time inference. Use autoscaling to scale resources based on traffic to optimize costs.
- Serverless Architectures: Consider serverless computing solutions (e.g., AWS Lambda) for on-demand scaling, where you pay only for the compute resources used during real-time requests.
- Batch Processing for Non-Urgent Tasks: Offload non-urgent, large-scale data processing tasks to batch jobs or use asynchronous processing where latency is not critical.
- A/B Testing: Conduct A/B testing or shadow deployments to compare different versions of the model and determine which one performs better in real-world scenarios.
- Latency and Throughput: Test the model for latency (response time per request) and throughput (requests per second). Ensure that the model’s performance meets the real-time requirements of the application.
- User Feedback: Gather user feedback in real-time to assess the model’s effectiveness and accuracy, particularly for use cases involving conversational agents or personalized services.
- Continuous Retraining: Regularly retrain the model with new data to keep it up to date, especially for real-time applications that continuously evolve (e.g., customer interactions or financial markets).
- Model Drift Monitoring: Implement monitoring systems to detect model drift, where the model’s performance degrades due to changes in the underlying data distribution.
- Versioning: Use model versioning (e.g., MLflow, DVC) to track model updates and manage the deployment of different versions in production.
- Bias Detection: Continuously evaluate the model for biases, especially when it interacts with real users in sensitive areas like hiring, healthcare, or legal services. Use fairness metrics to ensure equitable outcomes.
- Data Privacy: Ensure that the model complies with privacy regulations (e.g., GDPR, HIPAA) by anonymizing or encrypting sensitive data, especially if real-time applications involve personal or confidential information.
Building a private LLM for real-time applications involves careful planning, including data preparation, model optimization, infrastructure setup, and continuous maintenance. Ensuring that your LLM can provide accurate results with minimal latency is essential for delivering a seamless user experience. Focus on model efficiency, scalability, and cost-effectiveness to meet real-time performance requirements while maintaining data privacy and ethical considerations.
Optimizing for Real-Time PerformanceOptimizing for real-time performance in private Large Language Models (LLMs) is essential to ensure fast, responsive, and efficient operations in time-sensitive applications. Key strategies include minimizing latency and enhancing throughput, which can be achieved by optimizing model architecture, such as reducing model size through techniques like pruning and quantization. This helps retain model performance while making it more lightweight, enabling quicker responses.
Leveraging hardware acceleration with GPUs or specialized AI chips can significantly speed up computations, ensuring that real-time processing needs are met. Additionally, using techniques like model distillation allows for the creation of smaller, more efficient models that maintain high accuracy while reducing the computational load.
Caching frequently used responses and implementing efficient data pipelines further improve speed and responsiveness, allowing the system to handle large volumes of queries seamlessly. Real-time optimization also involves load balancing and scaling the system to handle traffic spikes while maintaining reliability. By continuously monitoring system performance and making incremental adjustments, businesses can ensure that their private LLM delivers the required speed and efficiency for real-time applications.
Securing Your Private LLMSecuring your private Large Language Model (LLM) is crucial for maintaining data privacy, protecting against unauthorized access, ensuring compliance with regulations, and safeguarding your intellectual property. Below are the key strategies for securing your private LLM:
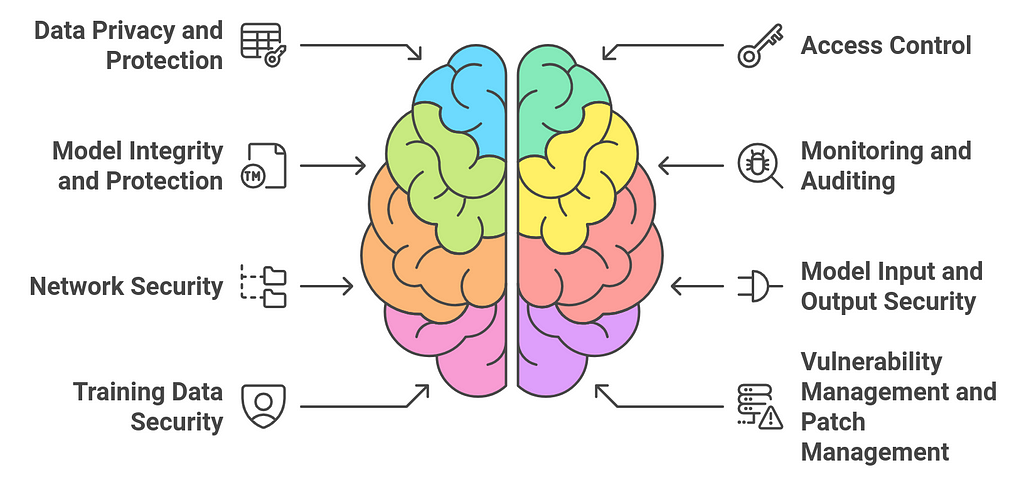 1. Data Privacy and Protection
1. Data Privacy and Protection- Data Encryption: Encrypt all sensitive data both at rest (when stored) and in transit (when transmitted over networks). Use strong encryption standards (e.g., AES-256) to ensure that any data processed or stored by your LLM is secure from unauthorized access.
- Anonymization and Tokenization: Anonymize sensitive information in the training and inference data to minimize privacy risks. Tokenization of sensitive personal information (e.g., names, addresses) is also important for data protection during model training and inference.
- Data Masking: Use data masking techniques when dealing with sensitive data to prevent exposure of actual data during testing or development phases.
- Role-Based Access Control (RBAC): Implement strict RBAC policies to limit who can access the LLM and associated resources (e.g., training data, model weights). Assign different levels of access to developers, data scientists, and administrators based on their roles.
- API Access Management: Secure API access by using authentication mechanisms such as OAuth2, API keys, or JWT tokens to ensure that only authorized users and systems can make requests to the model.
- Zero Trust Architecture: Adopt a Zero Trust security model, which means that no one (inside or outside the network) is trusted by default. Every request must be authenticated, authorized, and validated before being granted access.
- Model Watermarking: Use watermarking techniques to embed a unique identifier into the model’s outputs or weights. This helps in identifying unauthorized copies of the model, making it easier to track and prevent misuse.
- Model Encryption: Encrypt model weights and parameters during storage and transfer to prevent unauthorized access or theft of intellectual property. You can use secure multi-party computation (SMC) or homomorphic encryption for this purpose.
- Intellectual Property Protection: Use legal agreements, such as non-disclosure agreements (NDAs), with all stakeholders involved in developing or interacting with the model to protect your intellectual property. Implement safeguards to monitor and track the distribution of proprietary models.
- Activity Logging: Implement comprehensive logging and monitoring systems to track all interactions with the model, including who accessed it, what data was used, and what predictions were made. Use tools like ELK Stack (Elasticsearch, Logstash, Kibana) or Splunk for centralized logging and analysis.
- Audit Trails: Maintain an immutable audit trail that logs model interactions, changes to the model, and data access. This is essential for compliance, transparency, and accountability, especially in regulated industries like finance or healthcare.
- Anomaly Detection: Use machine learning and statistical methods to monitor for unusual activity or potential threats, such as large volumes of requests from a single user or sudden changes in model behavior.
- Firewalls and Network Segmentation: Use firewalls to protect your model’s infrastructure from unauthorized external access. Segment the network to isolate sensitive model components (e.g., training data, model inference) from less sensitive parts of your infrastructure.
- Secure Communication Protocols: Ensure that all communication between the model and users is secured with protocols such as HTTPS, TLS, or VPNs. This prevents interception and man-in-the-middle attacks during data transfer.
- Intrusion Detection Systems (IDS): Deploy IDS and Intrusion Prevention Systems (IPS) to detect and block any malicious attempts to breach your infrastructure.
- Input Validation: Implement strong input validation to prevent adversarial attacks or malicious inputs. Ensure that the model only processes valid and authorized data to prevent exploitation of vulnerabilities.
- Output Filtering: Prevent the model from generating harmful or biased outputs by adding post-processing filters that remove or modify any undesirable responses. This is especially important when the model is exposed to end-users.
- Rate Limiting: Apply rate limiting on API endpoints to prevent Denial of Service (DoS) or brute-force attacks from overwhelming your model infrastructure.
- Data Access Restrictions: Restrict access to training data to authorized personnel only. Use secure storage and encryption to protect sensitive data during training.
- Data Provenance: Track the origin of your training data to ensure that it is legitimate, non-toxic, and compliant with data protection regulations. Avoid using data sources that might introduce biases or violate privacy laws.
- Differential Privacy: Implement differential privacy techniques during model training to prevent sensitive information from being inferred or exposed based on the model’s predictions. This is especially useful when training with personal or sensitive data.
- Regular Security Audits: Perform regular security audits and penetration tests to identify vulnerabilities in the model and infrastructure. Use tools such as OWASP ZAP for automated security testing.
- Patch Management: Keep all software components up to date with the latest security patches. This includes updating libraries, frameworks, and dependencies used in building, training, and deploying the LLM.
- Bug Bounty Programs: Consider implementing a bug bounty program where security researchers can report vulnerabilities in exchange for rewards. This helps in identifying and resolving security issues proactively.
- Adversarial Training: Train your model to be resilient against adversarial attacks (e.g., input manipulation) by generating adversarial examples and incorporating them into the training data. This improves the model’s robustness and helps it recognize potential security threats.
- Model Hardening: Use techniques like input sanitization, robust optimization, and noise injection to harden the model against malicious attempts to alter its behavior.
- Regular Testing: Conduct regular security tests, including adversarial testing and fuzz testing, to identify vulnerabilities and weaknesses in the model’s ability to withstand attacks.
- Data Protection Laws: Ensure that your LLM complies with data protection laws such as GDPR, HIPAA, CCPA, or other regional privacy regulations. This includes obtaining consent from users before processing personal data, implementing data retention policies, and providing data access controls.
- Third-Party Audits: Engage third-party auditors to assess the security measures of your LLM and ensure that they meet industry standards and regulatory requirements.
- Incident Response Plan: Develop an incident response plan to quickly address security breaches, including data leaks, unauthorized access, or adversarial attacks. The plan should outline steps to contain, mitigate, and recover from security incidents.
- Backup and Recovery: Ensure that regular backups of the model and training data are performed to safeguard against data loss or corruption. Use encrypted backups and store them securely.
- Disaster Recovery: Implement a disaster recovery plan to restore operations in the event of a severe security incident or system failure. This plan should include recovery procedures for both the model and the infrastructure.
Securing a private LLM requires a multi-layered approach that covers everything from data protection to access control, infrastructure security, and compliance with regulations. Ensuring that your model is protected against unauthorized access, malicious attacks, and data leaks is essential for maintaining trust, safeguarding intellectual property, and ensuring compliance with legal and ethical standards. Regular monitoring, testing, and updates are crucial to keeping the model secure as new threats and vulnerabilities emerge.
Challenges and Best PracticesBuilding and deploying private Large Language Models (LLMs) for real-time applications presents several challenges, including data privacy, model scalability, and maintaining low latency. One major challenge is ensuring the security of sensitive data, as private LLMs handle confidential information that must be protected from unauthorized access. Addressing this requires strong encryption and compliance with privacy regulations like GDPR. Scalability is another hurdle, as private LLMs must be capable of handling growing volumes of data and user interactions without compromising performance.
To address this, businesses can implement cloud-based solutions with elastic scaling capabilities. Ensuring low latency is critical in real-time applications, which can be difficult due to the complexity and size of LLMs. Best practices for overcoming these challenges include optimizing model architecture with techniques like pruning and quantization, using distributed systems to handle processing demands, and leveraging specialized hardware for faster computations.
Additionally, maintaining a robust monitoring and feedback loop allows for continuous model improvement and adaptation to changing data. By following these best practices, organizations can build reliable, efficient, and secure private LLMs that excel in real-time environments.
Use Cases for Private LLMs in Real-Time ApplicationsPrivate Large Language Models (LLMs) offer significant potential for enhancing real-time applications across various industries. By leveraging private LLMs, businesses can ensure more control over their data, tailor the models to specific needs, and achieve improved performance and privacy. Below are some key use cases for private LLMs in real-time applications:
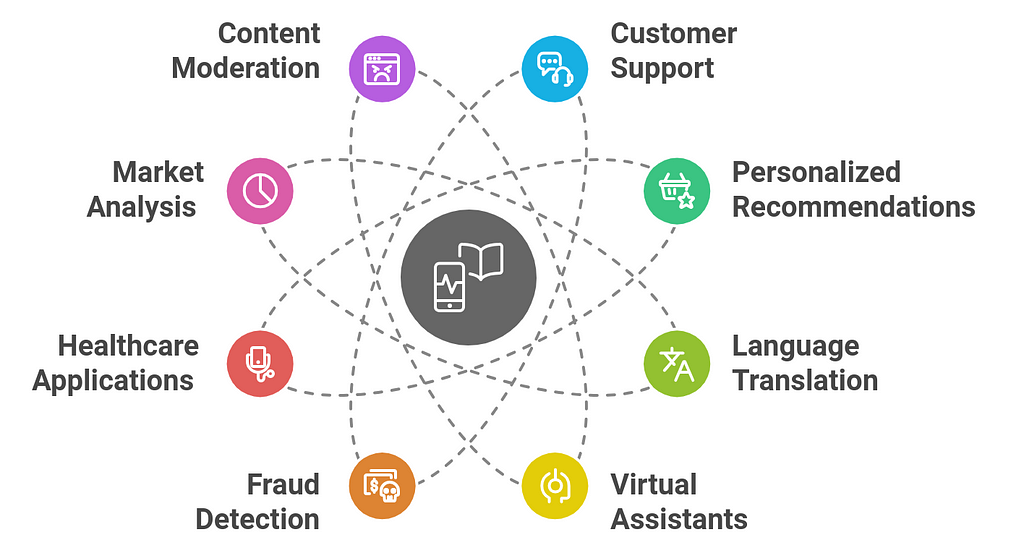 1. Customer Support and Chatbots
1. Customer Support and Chatbots- Real-Time Assistance: Private LLMs can be deployed to handle real-time customer queries, providing personalized and context-aware responses without relying on third-party solutions. This is especially useful for businesses that need to ensure privacy and maintain control over sensitive customer data.
- 24/7 Availability: Private LLMs can power chatbots for 24/7 customer support, responding instantly to customer inquiries, troubleshooting issues, or guiding users through processes like product setups or problem resolutions.
- Sentiment Analysis: These models can process and analyze customer messages in real-time to determine sentiment, allowing customer service representatives to prioritize high-priority or frustrated customers, improving satisfaction and retention.
- E-commerce: Private LLMs can analyze customer behavior, preferences, and browsing history in real time to deliver tailored product recommendations. By leveraging past purchase data, browsing patterns, and contextual preferences, the model can offer personalized experiences without compromising user data security.
- Content Recommendation: In media streaming or news platforms, private LLMs can process user interactions to provide real-time, personalized content recommendations (movies, articles, music, etc.), improving user engagement and satisfaction.
- Multilingual Communication: Private LLMs can be used to provide instant language translation for customer interactions or international teams. This can be used in real-time chat interfaces, email support, or video conferencing systems, enabling seamless communication across different languages without relying on public translation services.
- Sensitive Data Handling: For businesses operating in multiple regions, private LLMs can securely translate sensitive content while maintaining compliance with data protection laws, such as GDPR.
- Context-Aware Assistance: Private LLMs can enhance virtual assistants by making them more conversational and context-aware. Whether it’s handling personal calendar events, emails, or device control, a private LLM can operate seamlessly in real time to deliver responses or actions tailored to the user’s specific needs.
- Task Automation: In enterprises, virtual assistants powered by private LLMs can help automate a wide range of real-time tasks, such as scheduling, document creation, or even data retrieval from internal systems.
- Financial Transactions: Private LLMs can be deployed to detect and respond to potentially fraudulent activities during financial transactions in real time. By analyzing patterns and anomalies in user behavior (e.g., unusual spending habits or login locations), the model can flag suspicious activities, prompting immediate security measures.
- Risk Assessment: The model can analyze real-time data, such as payment information or device fingerprints, to assess the risk level of transactions, providing instant feedback to merchants or users.
- Medical Diagnosis Support: Private LLMs can be used to analyze patient data, symptoms, and historical medical records in real time, assisting healthcare professionals in making faster, more accurate diagnoses. By processing medical queries or recommending treatments, these models can provide decision support without compromising patient confidentiality.
- Clinical Monitoring: In a clinical setting, private LLMs can analyze real-time data from wearable devices (e.g., heart rate, blood pressure) and assist in detecting early warning signs of health issues, enabling prompt medical intervention.
- Market Sentiment Analysis: Private LLMs can process news articles, social media feeds, or real-time financial reports to assess market sentiment, helping financial institutions make faster investment decisions. These models can provide real-time summaries or sentiment scores of market conditions.
- Algorithmic Trading: By analyzing real-time market data, private LLMs can contribute to algorithmic trading strategies by predicting trends, automating trades, and responding to market changes immediately.
- Social Media and Online Platforms: Private LLMs can be used to monitor and moderate user-generated content in real time, identifying inappropriate language, hate speech, or spam. By analyzing text, images, and videos, these models can quickly flag or filter content, ensuring compliance with platform policies.
- Compliance: For industries that require strict adherence to regulations (e.g., financial services, healthcare), private LLMs can analyze communication channels in real time to ensure that content remains compliant with legal requirements.
- Inventory Monitoring: Private LLMs can help businesses manage inventory in real time by analyzing sales data, stock levels, and supplier information. By predicting demand fluctuations and recommending adjustments, the LLM can help companies prevent stockouts or overstock situations.
- Order Tracking: In logistics and shipping, private LLMs can process real-time data from multiple sources to track orders, identify delays, and communicate updates to customers or management.
- Real-Time Cybersecurity Monitoring: Private LLMs can analyze network traffic and logs in real time to detect potential security threats, such as malware, data breaches, or DDoS attacks. By leveraging contextual information, these models can generate alerts and recommend immediate actions.
- Threat Detection in Communications: In environments where sensitive data is transmitted (e.g., government agencies, financial institutions), private LLMs can scan communications for signs of phishing, malware links, or suspicious activity in real time.
- Contract Review and Legal Research: Private LLMs can be used by legal teams to review contracts, compliance documents, or regulations in real time. These models can flag potential legal issues, extract key clauses, and provide summaries, assisting legal professionals in making faster, data-driven decisions.
- Regulatory Compliance Monitoring: In regulated industries like finance, healthcare, and insurance, private LLMs can analyze real-time transactions, communications, and documents to ensure that operations comply with regulatory requirements.
- Invoice and Receipt Processing: Private LLMs can analyze scanned documents (invoices, receipts) in real time, extracting key information like amounts, dates, and vendor names. This can be used for automating accounting processes or integrating with enterprise resource planning (ERP) systems.
- Legal and Technical Document Parsing: Private LLMs can parse complex legal or technical documents in real time, helping teams extract relevant sections or identify key information to inform business decisions or risk assessments.
Private LLMs in real-time applications can greatly enhance efficiency, customer experience, and security by offering personalized, context-aware, and secure solutions. These use cases highlight the vast potential for deploying LLMs across different industries, from customer service and healthcare to financial markets and cybersecurity. By keeping the model and data private, businesses can ensure greater control over their operations, enhance data privacy, and meet compliance requirements.
Future TrendsThe future of private Large Language Models (LLMs) for real-time applications is shaped by several emerging trends that will drive innovation and improve performance. As AI technology advances, we can expect more sophisticated and efficient model architectures that provide higher accuracy with lower computational demands. Techniques like federated learning and decentralized AI will enable private LLMs to be trained and improved across distributed networks without compromising data privacy, making them even more secure and scalable.
The integration of AI hardware, such as specialized processors and quantum computing, will further accelerate the processing capabilities of LLMs, enabling them to handle real-time demands with minimal latency. Additionally, advancements in explainable AI (XAI) will help organizations better understand and trust their private LLMs, fostering greater transparency and accountability in decision-making.
Continuous improvements in natural language understanding and multimodal capabilities will make private LLMs more adaptable to a wider range of applications, from conversational AI to data-driven automation. As businesses demand more personalized, responsive solutions, the future of private LLMs will be marked by greater customization, enhanced real-time performance, and robust privacy features.
ConclusionIn conclusion, building a robust private Large Language Model (LLM) for real-time applications demands a balanced approach, focusing on security, scalability, and performance. By selecting the right infrastructure, implementing strong privacy measures, and training the model on relevant data, businesses can create an LLM tailored to their specific needs. Real-time performance can be achieved by optimizing the model for low latency and high throughput, using techniques such as pruning and quantization to boost efficiency. It’s also important to ensure continuous monitoring and updates to adapt to evolving data and user demands.
With careful attention to these aspects, organizations can develop a private LLM that enhances user experiences while maintaining data integrity and security. The key to success lies in a proactive, iterative approach, ensuring that the model stays efficient, relevant, and capable of meeting the challenges of real-time applications over time. Ultimately, investing in a well-constructed private LLM can provide long-term value and a competitive edge in an increasingly data-driven, AI-powered world.
How to Build a Robust Private LLM for Real-Time Applications? was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.